Abstract
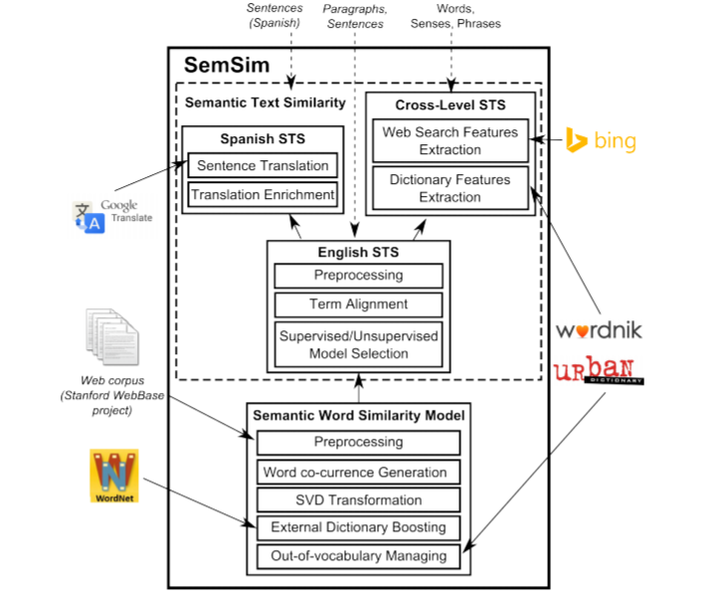
Semantic textual similarity is a measure of the degree of semantic equivalence between two pieces of text. We describe the SemSim system and its performance in the *SEM 2013 and SemEval-2014 tasks on semantic textual similarity. At the core of our system lies a robust distributional word similarity component that combines Latent Semantic Analysis and machine learning augmented with data from several linguistic resources. We used a simple term alignment algorithm to handle longer pieces of text. Additional wrappers and resources were used to handle task specific challenges that include processing Spanish text, comparing text sequences of di↵erent lengths, handling informal words and phrases, and matching words with sense definitions. In the *SEM 2013 task on Semantic Textual Similarity, our best performing system ranked first among the 89 submitted runs. In the SemEval-2014 task on Multilingual Semantic Textual Similarity, we ranked a close second in both the English and Spanish subtasks. In the SemEval2014 task on Cross–Level Semantic Similarity, we ranked first in Sentence–Phrase, Phrase–Word, and Word–Sense subtasks and second in the Paragraph–Sentence subtask.